Speech synthesis is technology that turns written text into spoken audio, also called text to speech, used for voiceovers, accessibility, and narration. Modern AI voices sound natural enough to stand in for recording on drafts, scratch tracks, and some final narration. Descript's text to speech and AI voices turn a script into clean spoken audio in seconds.
In Stanley Kubrick’s groundbreaking 1968 epic, 2001: A Space Odyssey, HAL 9000, a talking supercomputer converses in an easy, eerily human-like voice. Kubrick’s sentient machine left a lasting impression on our collective imagination. And ever since, developers and programmers have since been bent on making machines talk in ways that are not only understandable but also believable.
Apps, phones, computers, and even cars now come with sophisticated built-in text-to-speech tools. GPS devices and virtual assistants like Siri and Alexa can detect our voices and reply in kind — sometimes in ways that surprise us.
What is speech synthesis?
Speech synthesis — also called text-to-speech, or TTS — is an artificial simulation of the human voice by computers. Speech synthesizers take written words and turn them into spoken language.
You probably come across all kinds of synthetic speech throughout a typical day. Helped along by apps, smart speakers, and wireless headphones, speech synthesis makes life easier by improving:
- Accessibility. If you’re visually impaired or handicapped, you might use TTS for reading text content or use a screen reader to speak aloud words. TikTok’s Text-to-Speech synthesizer, for example, is a widely used accessibility feature, allowing anyone to consume visual social media content.
- Navigation. You can’t look at a map while you drive, but you can listen to instructions. No matter where you’re going, most GPS apps can deliver helpful voice alerts as you travel, some in multiple languages.
- Voice assistance. Intelligent audio assistants like Siri and Alexa are great for multitasking, allowing you to order pizza or hear the weather report while you’re engaged in other physical tasks (e.g. washing the dishes). While these assistants occasionally slip up — accidentally ordering $200 worth of laundry detergent, playing lullabies instead of news podcasts, etc. — and are often designed as subservient female characters, they do sound quite lifelike and they tell a pretty good joke or two.
What is the history of speech synthesis?
At the 1939 World’s Fair in New York City, Homer Dudley of Bell Laboratories demonstrated the world’s first functional voice synthesizer: the Voder. The enormous organ-like apparatus required a human operator to manipulate its keys and foot pedal. “Good afternoon, radio audience,” it uttered before marveled spectators, sounding more alien than human, yet remarkably intelligible. The Voder set off a wave of innovation.
Over the next few decades, researchers built on the Voder. In the late 1950s, the first computer-based speech synthesis systems were developed, and in 1961 Bell Laboratories again made history when physicist John Larry Kelly Jr. made an IBM 704 talk. That same year, an IBM's 7094 mainframe computer sang the folk song “Daisy Bell,” inspiring a climactic scene in Kubrick’s 2001 (the movie is truly an example of life imitating art and art imitating life.)
But it wasn't until the ’70s and ’80s, with the arrival of integrated circuits, that commercial speech synthesis products finally emerged in telecommunications and, notably, video games. One of the first speech synthesis integrated circuits was the Votrax chip, which made computer-generated sounds to mimic the human voice and was used in arcade games like “Gorf” and “Wizard Of Wor.” In 1980, Texas Instruments made a splash with its Speak N Spell synthesizer, which was used as an electronic reading aid for children.
Standard computer operating systems have included speech synthesizers since the early ’90s, mainly for dictation and transcription. Today, TTS serves all kinds of purposes, and synthetic voices have grown impressively accurate thanks to advances in artificial intelligence and machine learning. In some cases, the smooth tones of machine voices can be nearly indistinguishable from our own.
How does text-to-speech work?
As you might imagine, teaching a machine to speak is no easy task. Rithesh Kumar, who leads Overdub Research at Descript, is well aware of the difficulties. “Human speech is very complex,” he explains. There are three main reasons why:
- Every human has a unique voice texture. Your voice starts down in your lungs. You exhale to create an airstream that passes over your vocal cords, which vibrates to produce sounds. The higher the rate of vibration (or frequency) the higher the pitch. Your throat, nose, and mouth then act as a resonating chamber to turn those buzzing sounds into your unique voice.
- Words and sentences can be spoken in countless ways. We all speak with different pacing, pitch, and intonation, depending on what’s being said, how it’s being said, and who is saying it. Think of accents, for example.
- Audio is fundamentally noisy and unstructured. Thanks to factors like room tone, reverberation, and the nature of recording conditions, the same voice can sound different depending on the context. TTS systems, at least to some extent, need to replicate these factors to sound like the voices we’re used to hearing.
There are two main steps involved in turning text into speech:
Text conversion
The computer starts by determining what to say, and then analyzes the text to determine how to say each word based on context. The same written text can have multiple meanings and pronunciations, so the computer has to figure out what it’s going to say to prevent mistakes and reduce ambiguity in the output.
Take homographs, words spelled the same but not necessarily pronounced the same. For example, the word ‘bow’ might refer to a knot tied with loops and loose ends (bō), but it can also mean bending one’s head or body as a sign of respect (bou). A speech synthesizer might refer to the broader context to determine the proper pronunciation.
Speech synthesizers also need to turn words into phonemes — the distinct units of sound that comprise a spoken language and make words sound different from each other. The vowel ‘a,’ for example, is a phoneme, and there are many ways it can be said. You may not realize it, but we also do naturally break down words into phonemes when we speak.
In theory, this is simple — the computer draws from an inventory of words and their corresponding pronunciations — but it’s more complex in practice. Intonation, rhythm, and speech rate vary according to cues in the text, and phonemes in words change depending on the context. “We need to teach machines to handle all these complexities to generate realistic-sounding speech,” says Kumar. Sound sequencing is one of the most challenging problems in speech synthesis.
Sound production
The computer then converts phonemes to sounds — audio waveforms — producing what you hear. There are two main ways it does this:
- Using human recordings. Known as concatenative TTS, the speech synthesizer uses recorded snippets of human speech from an inventory, and then arranges them into words. “This method tries to populate a bank of fundamental audio units and generates speech by stringing those together in a way that sounds realistic,” says Kumar. Using pieces of human speech generally limits the synthesized output to a single voice and language. “Almost no modern-day TTS system uses this method anymore, barring Apple’s Siri.”
- Using computer-generated sounds. Known as statistical parametric TTS, the computer generates audio using basic sound frequencies to mimic the human voice, like a musical instrument. Making sounds from scratch allows the speech synthesizer to say anything, including foreign words or even words that don’t exist. Computer-generated sounds are helpful for GPS navigation tools, for instance, which need to be able to read out all kinds of new place names. “This method is more flexible, more expressive, and natural,” says Kumar.
Until recently, voice synthesis software based on human recordings tended to sound more natural than the artificial sounds generated by computers. But machine learning has revolutionized speech synthesizers, blurring the lines between human recordings and computer-generated sounds.
“We use very large neural networks [a series of algorithms] and train them on large amounts of data — speech from hundreds, even thousands of people — to learn the intricacies of human speech modeling in an automated way, rather than hand-engineering each component,” explains Kumar. In fact, with only a few sentences of speech from a new speaker, machine learning systems can now clone human voices.
How Descript uses speech synthesis to make editing easier
Overdub, Descript’s text-to-audio feature, also pushes the limits of machine-learning-assisted TTS. With Overdub, you create a text-to-speech model of your voice to create voiceover for videos or perform corrections on recordings through text. In other words, you simply type the words that your audio or video tracks are missing. There’s no need to go back and rerecord anything.
“This is a groundbreaking use case for audio and video editing, since rerecording and pasting to fix mistakes is cumbersome,” says Kumar. He believes we’re “less than a year away” from a future where synthesized speech is as good as human speech.
How to add Overdub to a project
To use Overdub, you need to either create a custom Overdub voice or use one of our pre-made Stock voices.
Once your Overdub voice has been trained and activated, you can open a new project and start using it. You’ll need to associate the Overdub voice to a speaker label in your project. You can do this one of two ways:
- First, select the voice in the speaker label dropdown menu. Overdub voices will be listed at the bottom of your speaker label list under the "Create from voice" speaker label section.
- Alternately, if a label already exists for the speaker in question (e.g. if you've already imported and transcribed a recording), you can associate the Overdub voice to an existing speaker label. Just click on the label, select Edit speakers, then select the Overdub voice from the dropdown button on the right.
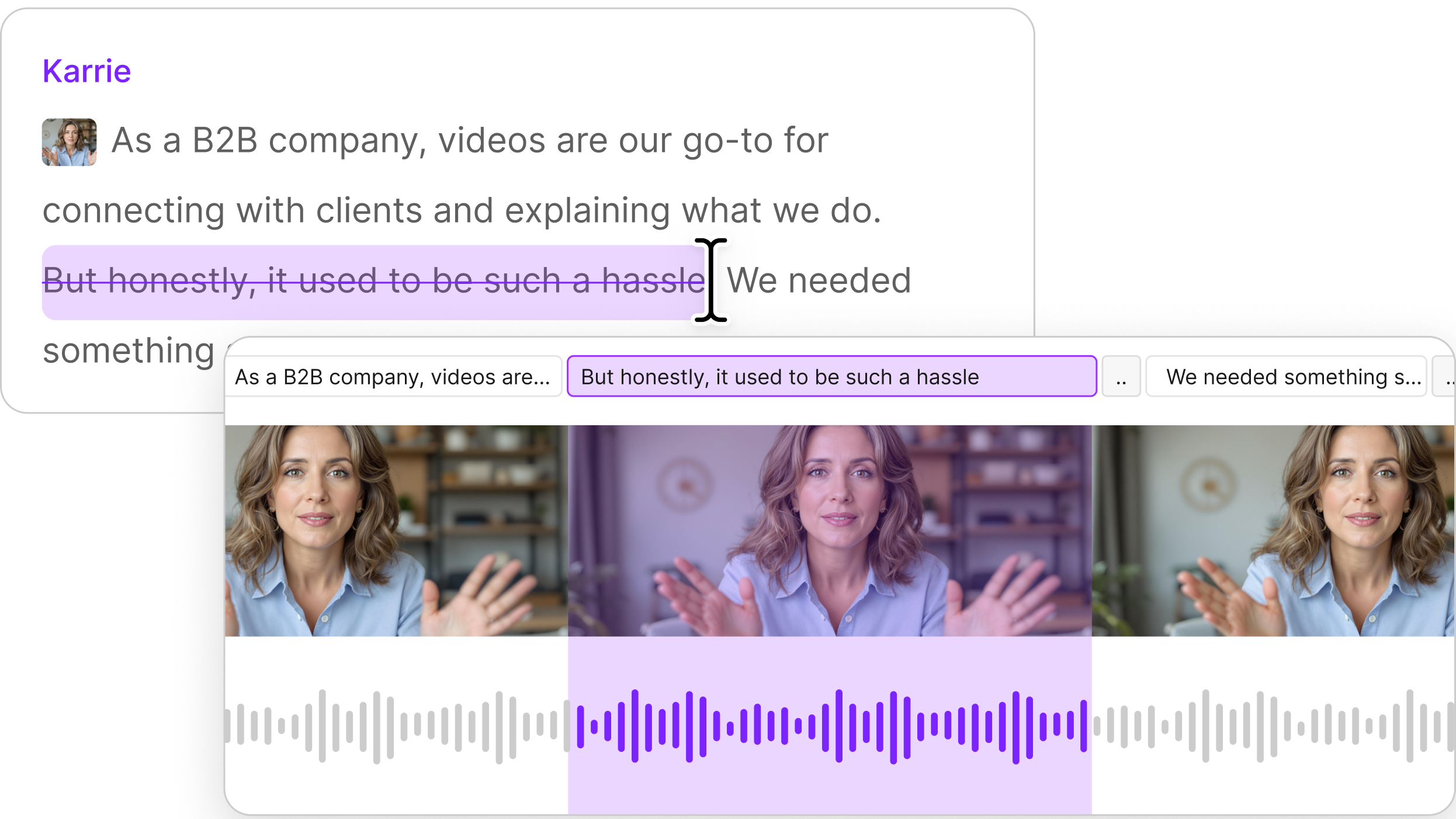
Creating an Overdub is then as easy as typing on a blank line just as you would in any text editor. You can do this either in a new Composition, or by creating a new line in the middle of an existing recording.
After waiting a few seconds, you’ll see the message ‘Generating Overdub’ while the speech audio is created. Once complete, the blue underline will disappear and a new waveform will appear in the timeline below. You can also insert or replace audio in the middle of a recording — click the location you’d like it to appear in, highlight a section of text, and press the letter D in the pop-up dialog. When finished, click the Overdub button or press Enter.