Most MCP servers just wrap an API. When you're building a platform from scratch, it's tempting to wrap it, ship that, and give yourself a pat on the back. Our MCP was a wrapper, too, for about a week. This is the story of what we learned building both an Agent API and an MCP for Descript, watching the two pull apart in ways we didn't expect, and the changes we made.
One agent API > 20 individual endpoints
When we started, we didn’t have a useful public API at all, so the obvious move was to expose a few endpoints for our popular features: one to remove filler words, one to add captions, one to apply Studio Sound, and so on. We almost did that. But instead, we decided to consolidate the core of our API on a single agentic endpoint: Underlord, the editing agent inside Descript.
There were practical reasons to start here. Wrapping our existing agent would be the fastest, most flexible way to expose the full breadth of what Descript can do. Every capability the agent had would be instantly available, and we’d avoid maintaining an ever-growing list of public endpoints, each with its own design and parameters to nail down.
But the deeper reason was to future proof our product. When you're building AI features, a fixed set of parameters locks you to today's capabilities. Say we adopt a model that's better at detecting humor, or we teach "find good clips" to highlight by speaker — none of that maps cleanly onto parameters.
And edits rarely happen alone: editors add layouts, apply Studio Sound, layer on captions. They're orchestrating a series of changes, each with its own complexity. A parameter list can't keep up with that.
A single agent endpoint fits both realities. You tell it where you want to end up or describe an entire workflow of edits; and it adapts and grows as our models do, instead of pinning us to a fixed list. As users adopt the platform, we learn from what they're trying to do and improve the API around it, because we've exposed as much of it as we can from the start.
Dipping our toes in the MCP waters
We always had an MCP somewhere on our backlog. But I was an impatient PM — I knew Descript could do a lot more once it connected to other tools and I wanted to prove it. So I vibecoded a local MCP server on top of our API, just to see what would happen. Building the thing beats scheduling it.
At our internal hackathon, it was startling how much anyone in the company could do by stitching Descript together with everything else: turn a webpage into a draft script, then into an avatar video. Have Claude analyze a YouTube video for its style, then ask Underlord to apply that style to your own recordings. But we also started to see a clear split between who was using the API and who was using the MCP, and the different jobs each had in mind.
Our engineers built a translation Chrome extension on top of the API that would dub any video into a lip-synced version, so the original speaker appears to talk in whatever language you pick. Our Support and Sales teams used the MCP to build flows that turned help center articles drafted in Notion into how-to videos.
That's when we realized the MCP is a different product from the API, and that people had different expectations for it. If we were going to ship something great, the MCP needed to be its own product, with behaviors that differed from both the API and our in-app agent.
Same agent, different places → different expectations
The agents behind the API and MCP are built on the same Underlord core that helps you edit in the Descript app. But it's not as simple as wrapping an API around the agent. In each context, you expect the agent to behave differently.
The app agent is for direct action. It has the most context and the most license to interrupt. It knows what you've selected, which composition you're looking at, and that you're sitting in front of the app, ready to answer follow-up questions. Because it interacts with you live, it's optimized for interaction and speed. Underlord users have the same profile as our historical video editors: people with a lot of taste and discernment who might not be experienced editors themselves. They're looking to direct Underlord and lean on it for best practices.
The API agent is for automation. It comes into a project with very little context and is expected to finish the task on its own. If you call an API to get a job done, you'd be annoyed to come back 15 minutes later to find it waiting for you to answer a single follow-up question, but perfectly happy if it takes an extra five minutes to be thoughtful and finish the whole thing independently. We also knew from talking to customers that people building on the API were scrappier and more technical, and expected to use it for bulk, templated tasks with predetermined instructions that run the same way every time.
The MCP agent is in the middle. It could be interactive, helping the user translate intentions into Descript-specific editing tasks, or it might one-shot a task as part of a broader workflow. It could be running on a schedule with no one at the wheel. And the tasks people want it for are different, too: they rely on the MCP to orchestrate work between Descript and other tools — pulling recorded media from one source into Descript for a rough cut, or turning docs from Notion into a narrated video.
These norms weren't rigid, but they helped us think about how to differentiate and optimize for each use case. Three levels of context and supervision meant three sets of harnesses and defaults.
There's a ceiling on how interactive a video tool can be inside a chat protocol. You can't watch a video in a chat window, and you can't grab the timeline and nudge a clip by hand. Part of designing an MCP is being honest about what belongs there and when we should send users to the rich Descript UI.
What belongs: uploading media, kicking off work, seeing progress while a long job runs, and getting a readable overview of what the agent changed. The MCP's job isn't to rebuild the editor in text. It's to let an agent drive the parts that translate to chat, and bow out cleanly for the parts that don't.
So the Descript API is documented for humans to automate workflows, the in-app agent is documented for human interaction, and the MCP is documented for agents to both automate and surface interactively.
Which is the real lesson: a good MCP isn't the API in a different hat. It's a different, more nuanced product. That's easy to miss, because once you have an API, an MCP looks like a simple transformation you can ship in an afternoon. And it works — as a prototype. But the gap shows the moment a real agent starts using it. To ship the MCP with confidence, we had to change some things.
Different defaults for the API and the MCP
Transcription
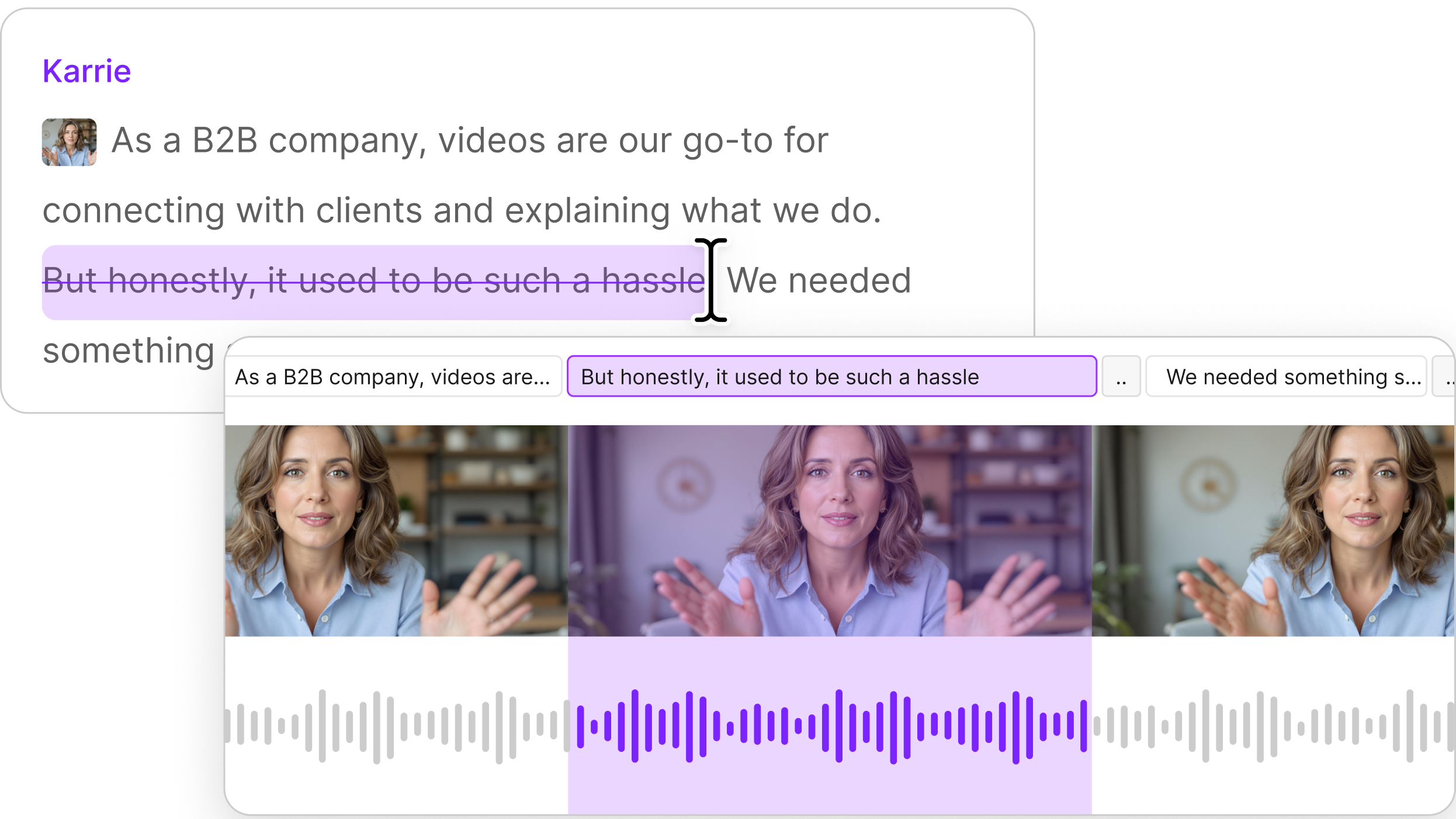
The clearest example of different expectations, unsurprisingly, was the transcript. We didn't expose transcript export as a separate endpoint at first, and it was immediately the feature nearly every early user asked for. But the request meant different things to different people.
To an API caller, a transcript is a deliverable: something to fetch, store on their side, and analyze later. A clean, finite endpoint, typically pulled at export time.
To an MCP user, a transcript is almost never the goal — it's the context the agent reads to understand a project before deciding what to edit next. Working memory, not output.
The needs diverge in the details, too. The agent wants the transcript quickly, because reading it is just an interim step, and it doesn't need much — the words and the chapter markers are enough. The API just wants it handy for when someone asks for it. Exposing the transcript only for published projects was a fine endpoint for the API user and not good enough as an agent tool: it served the "store it for later" case but wasn't fast enough for "what's in this composition right now."
So we rebuilt the transcription tool with one endpoint: it both returns plaintext instantly without publishing, and cant return richer formats when paired with the publish endpoint.
Asking follow-ups
When the agent isn't sure what you want — which clips, how long, what style — the most useful thing it can do in the app is ask. That back-and-forth is the expectation there; you're already in the loop. To a batch API job, it's a bug: there's no human to answer, and a job that stops to ask is just a job that hangs, and wastes your time. So the API defaults to making its best assumption and finishing. The user sees the results, then tunes their prompts to improve future batches.
The MCP keeps the choice open — its agent might one-shot the task, hold a conversation, or run unattended on a schedule — so it's free to clarify first when a human is there. Same agent, opposite posture, because one is talking to a person and the other is talking to a script.
Under the hood, it's an "ask follow-ups" flag backed by a different harness. The same capabilities are available across the board; the defaults and expectations differ. The principle we landed on: don't hard-code the behavior. Expose it, set a smart default, and let the use case decide.
Conversation memory
Conversation history, meanwhile, blurred the line between the app and the MCP. We recently added the ability to continue a prior conversation with our agent in the app. The question was whether histories should be on by default across sessions and surfaces. We split the answer by surface:
- The MCP defaults to continuing the conversation, since an interactive session usually means "keep going from where we were." It won't know about edits you made in the app — that's a different surface. So rather than hard-code it, we let the agent know history exists and choose whether to use it.
- The API does not continue a conversation unless you pass a conversation ID, because API jobs are typically standalone and async.
- In the app, you always see MCP and API conversation history when you come back, so you have full context on what happened in the project and why. That matters most when you're reviewing work and want to know what changed.
Is it working? The (honest) early numbers
It's still very early for us. The API landed in March as an open beta, and our MCPs launched in the Claude and ChatGPT marketplaces in late May.
Before we announced anything to our users, just being listed in those public directories grew platform usage 10x in the first two weeks. No surprise there — the MCP opens the platform to a much broader set of users.
What they're doing with it backs up everything we designed for. The most common pattern isn't a vague "make me a video." It's hyper-specific, spec-driven composition work from people who aren't professional editors but have strong sensibilities: exact fonts, hex colors, positions, durations, 4K canvases, beat-synced cuts. They use natural language to hand an agent content from a source and give it precise creative direction.
The range is wider than we expected: a Spanish-language creator running a 9:16-reformat-and-caption pipeline (the single heaviest user one week), loan officers assembling 4K multi-take marketing videos, webinar teams running name-canonicalization and caption audits, Instagram Reels cut to a target BPM.
The second most common pattern is plain transcript inspection — the very use case that caused us to rebuild the transcript tool. Some of this is happening in the open: one user recorded their whole Claude + Descript session and posted it on YouTube.
What we'd tell you if you're building an MCP
If there's one thing we'd pass on to anyone building an agent platform, it's this: the moment you have both an API and an MCP, you'll be tempted to treat the second as a fork of the first. Resist the urge. They can run on the same engine and still be different products, because they meet different users with different context, patience, and goals.
The quality of each comes from designing for those differences on purpose: different defaults, different tools, different harnesses. Most of that work is subtle, but it's the difference between an MCP that technically works and one people reach for on their own. So far, Descript users are doing exactly that.
Next: why some agents skip the MCP
The MCP has quickly become our dominant platform surface by traffic. But a segment of heavy users keep going straight to the raw API with their own LLMs — which complicates the tidy story that the API is just for human automators. We'll break down what they're doing, and what it means for how we build the API, in the next post.