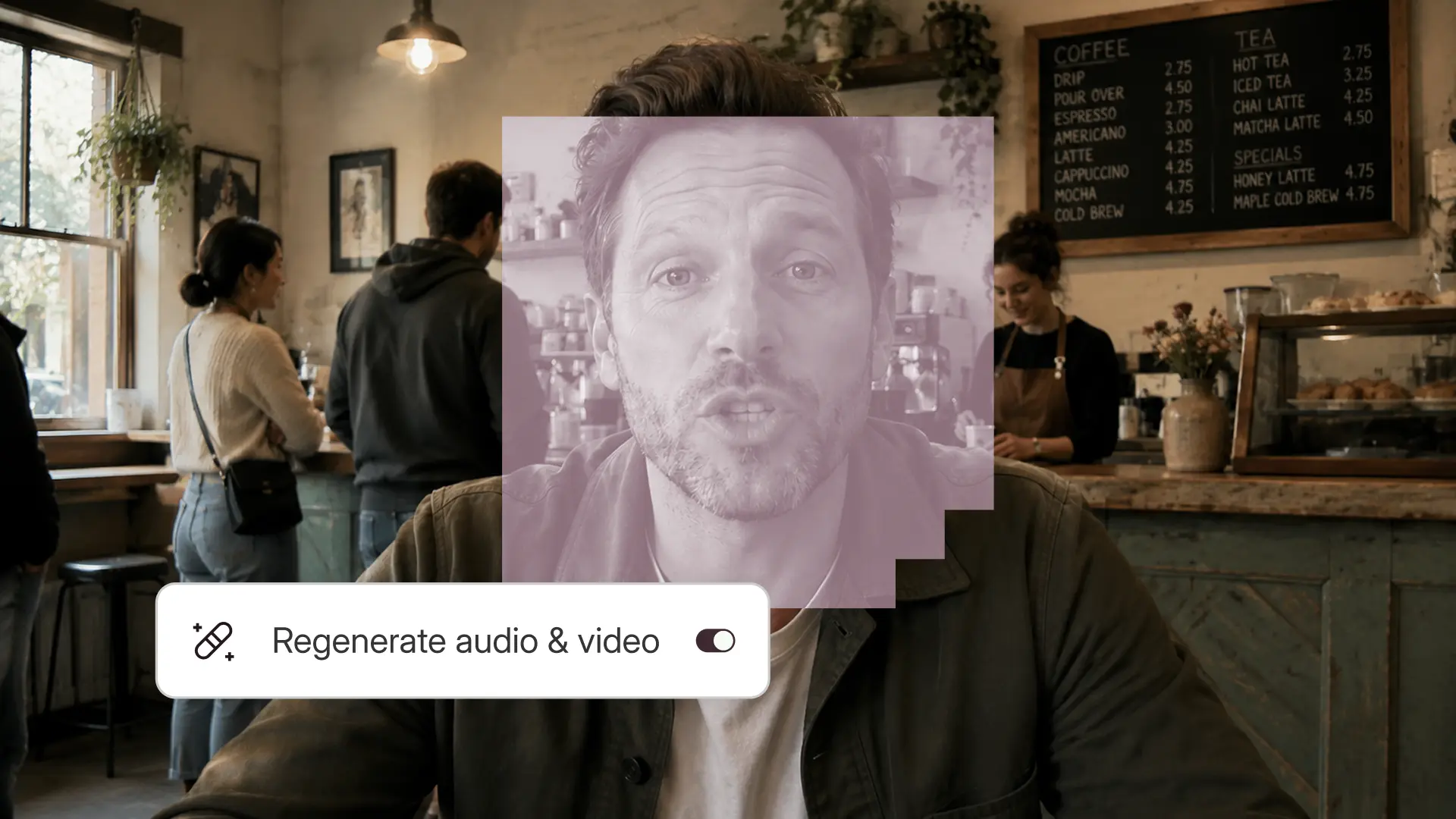
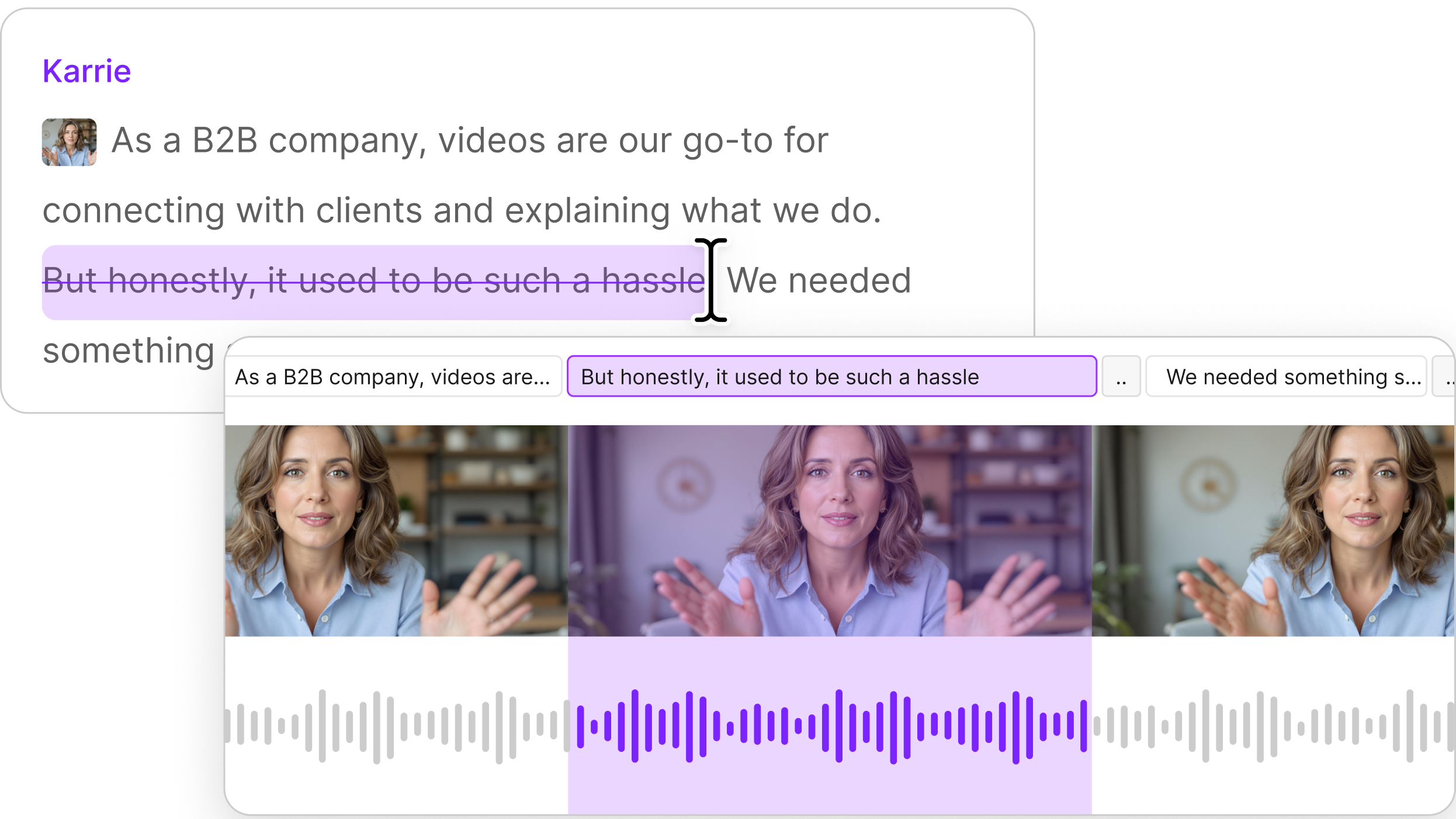
You've seen AI-generated images and videos everywhere on social media—some meant to fool people, some just for fun. Most are just AI slop. But can AI actually make something useful?
The key to avoiding slop with these tools is injecting your own human creativity, direction, and taste. But with so many AI models out there—Veo, Sora, PixVerse, Hailuo—how do you know which ones are worth using?
I tested 11 different AI image and video generators on a real project to find out. The good news: All of them are available in Descript, so you can use the best model for each task without juggling multiple accounts and subscriptions.
Here's what I learned about which models actually deliver.
What I tested
I tested Descript's AI tools while making an actual presentation. Could they handle custom stock images, brand asset variations, and standout “wow” moments?
These tasks let me stress-test common AI weaknesses: rendering human anatomy, accurate text, iterating on feedback, and using reference images.
For video, I added two more challenges: animating a reference image without step-by-step instructions, and understanding complex action sequences.
Access and workflow
Before we get to the results, here's how to access the models in Descript: under AI tools, select "Generate an image" or "Generate a video", then click the cube on the bottom right to choose your model.
To prompt the model, you can either just write a prompt alone, or attach a reference image and refer to that image in your prompt — for example, “Reimagine this family portrait in an abstract painting style.”
Each generation uses tokens, which refresh monthly. If you run out, you can pay to top up your account.
Images generate four at once, so your actual cost is 4x the listed price. You can refine any result with follow-up prompts.
Tip: Everything you generate gets saved to your project’s AI Assets folder, which fills up quickly. Getting organized early will save you headaches later.
Image generation: The contenders
Flux Dev
Flux Dev showed promise but had critical flaws. The family photos? Uncanny valley nightmare fuel. Instead of approachable, I got frightening.

Remove humans and Flux Dev improves dramatically. Text was legible, compositions solid. For environmental scenes without people, it's viable.

Flux Kontext
Flux Kontext goes stylized and moody—darker tones, candid feel. It didn't fit my optimistic presentation, but could work elsewhere.

Text rendering was solid and consistently readable, which was a big plus since many AI models struggle here.
The standout? Reference images. Flux Kontext matched styles well and could insert brand assets into new scenes coherently. No Photoshop marathons required.
Follow-up prompts worked great—it changed what I asked for and left the rest alone.

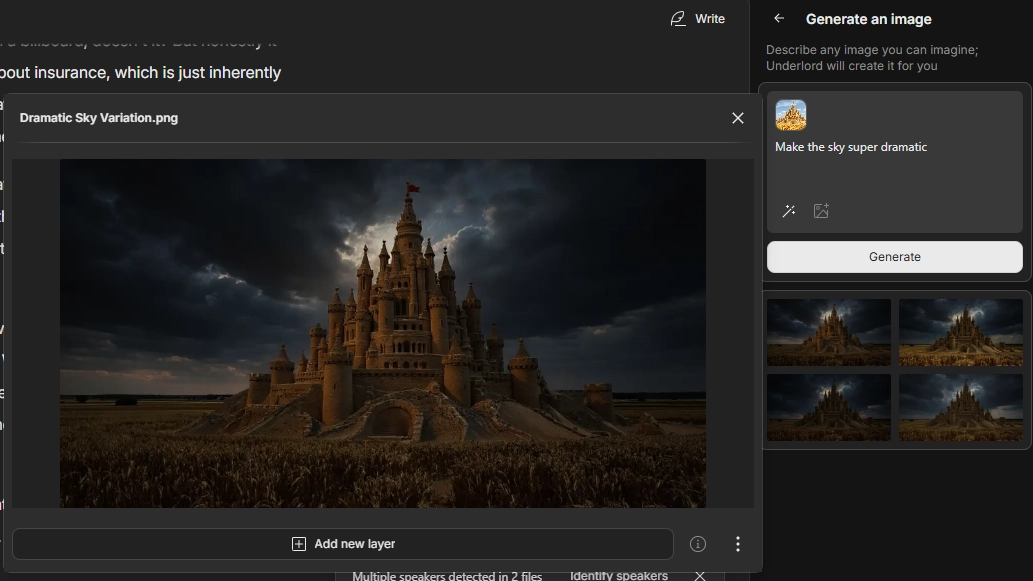
One thing to note: everything came out widescreen by default, which worked great for my video integration but might need cropping for other uses.
GPT Image 1
GPT Image 1 gave me mixed results: decent photorealism, bad anatomy.

Reference images produced odd artifacts that made renders unusable. It did match styles decently, though.
Where GPT Image 1 really impressed me was with complex prompts and text. It understood multi-part instructions better than most models I tested, and the text rendering was nearly perfect.

Nano Banana
Nano Banana nailed the polished corporate stock photo look. Bright lighting, clean aesthetics, and solid anatomy—nothing uncanny.

Complex prompts went surreal instead of literal, but it responded well to edits.
Reference images were hit-or-miss—beautiful when it worked, but it ignored them half the time. That meant wasting tokens on unusable renders.
Text was the biggest letdown. Nano Banana struggled more with legibility than other models I tested.

Like GPT Image 1, this model defaulted to square outputs.
Qwen
Qwen was a rollercoaster. On its very first render, it produced the most photorealistic image in my entire comparison: a prairie landscape that was genuinely convincing, if not exactly beautiful (and I'm a hard sell because I live in the prairies!)

But then it went downhill. Things were cartoonish or awkwardly stylized, quality was unpredictable, and anatomy was hit-or-miss.

Edits redrew the entire image instead of changing specifics. Reference images flopped. And text was often gibberish.
Overall, this one was a pass for my project.
My pick for images: Flux Kontext
Flux Kontext won for images. Editing precision, strong reference handling, readable text. The aesthetic won't fit everything, but it's the most versatile option.
Video generation
Images are nice, but video is harder.
Descript’s AI videos cap at five seconds for now (though you can slow them down to stretch length). The resolution isn’t as sharp as traditional footage, but every clip renders in widescreen, which at least makes compositing into larger projects straightforward.
I ran two tests:
- Animating a branded reference image
- Handling a complex scene with camera motion, text, and multiple elements
Tip: During the first test, I accidentally tripped the automatic content filters. At first, I couldn’t figure out why certain models refused to generate my clips... until I realized my reference image featured cartoon knives. The system never explained the block, which was frustrating, but it’s a good reminder that model safety filters can be triggered by surprisingly innocent details. When working with AI video, it’s worth double-checking your source materials before you hit generate. (For what it’s worth, Descript doesn’t deduct any credits for generations that come back with an error message).
PixVerse
PixVerse impressed immediately. Text was realistic and correct—a genuine win. Overall realism was fair.
It refused my knife-filled reference (probably due to content filters), but worked beautifully with others. Smooth, practical animation—best of the bunch.
Hailuo 02
Hailuo 02 was the only model that nailed my complicated camera direction. I asked for a text reveal and it actually revealed instead of just showing text the whole time. Almost perfect.
When I tested it with the reference image, it showed promising contextual awareness. The model understood what elements should move in the animation and what should stay static. It also executed details (like steam rising from a pot) quite naturally.
But stylistic consistency failed. My line drawing reference became photorealistic instead. Hailuo wanted to do its own thing.
Kling
Kling created realistic video with all key elements, but text was gibberish. Reference images went off the rails—it added bizarre elements I never requested and butchered text. A miss.
Wan 2.2 Turbo
Wan was my least favorite. Ignored camera direction, added things I didn't ask for, skipped text entirely. When it did animate, it garbled text into nonsense. Every other model did something better.
Veo 3.1
Veo 3.1 impressed. Realistic video, understood complex prompts, improvised compelling camera work. If only it got the text right—would've been the winner.
The best part of Veo 3.1's offerings were the animations. The first reference image of a chef and some knife-wielding crabs turned into a 5-second clip of a chaotic kitchen scene complete with the chef saying "Stop! Stop! You're chopping too fast!" and the crabs skittering around the table. I found it delightful. The second animation was pretty good too—the flags in the image were flying, along with some other pretty nice features. It wasn't perfect, but definitely one of the best options.
Sora 2
Sora was mostly solid: it did well with my complex prompt, and using reference images produced a pretty true-to-life animation with synchronized sound. But it changed the image color in both reference prompts for no perceptible reason.
My pick for video: Veo and PixVerse
No model delivered on everything. My advice: Match the model to your task. Pricier ones deliver on realism and scene logic, but PixVerse impressed as a solid middle ground.
Here’s what I’d recommend:
- Veo 3.1 for its understanding of a complex reference image. Worth the cost.
- PixVerse for efficient, clear animations that need readable text. Good value for your credits.
Despite the quirks, these tools are a creative leap. A few years ago, making even a short video sequence would’ve taken a team and a budget. Now, you can do it in a single afternoon. The key is knowing which model to trust for which job, and experimenting until you find a great output.
Don't be afraid to experiment
One last tip: Don't be afraid to experiment with multiple models for the same prompt. These tools are still evolving rapidly and Descript regularly adds new models and updates existing ones. What doesn't work perfectly today might be solved in the next update.
Models that struggled with one thing excelled at another. Generate variations—tokens replenish monthly, so treat early projects as experiments.
We're at the beginning of a new era. The barrier to creating visuals is dropping to almost zero. The only limit now is imagination.