








What type of content do you primarily create?



With ChatGPT's new multimodal features, like the ability to generate images with DALL-E and the ability to browse the internet, you might wonder exactly how these features work and what the constraints are.
We've dug into the backend for you so you can stop getting frustrated by "Content Policy Restrictions" and understand why ChatGPT is listening (or not listening) to your requests.
 |
Here's the rundown of the current policies around ChatGPT.
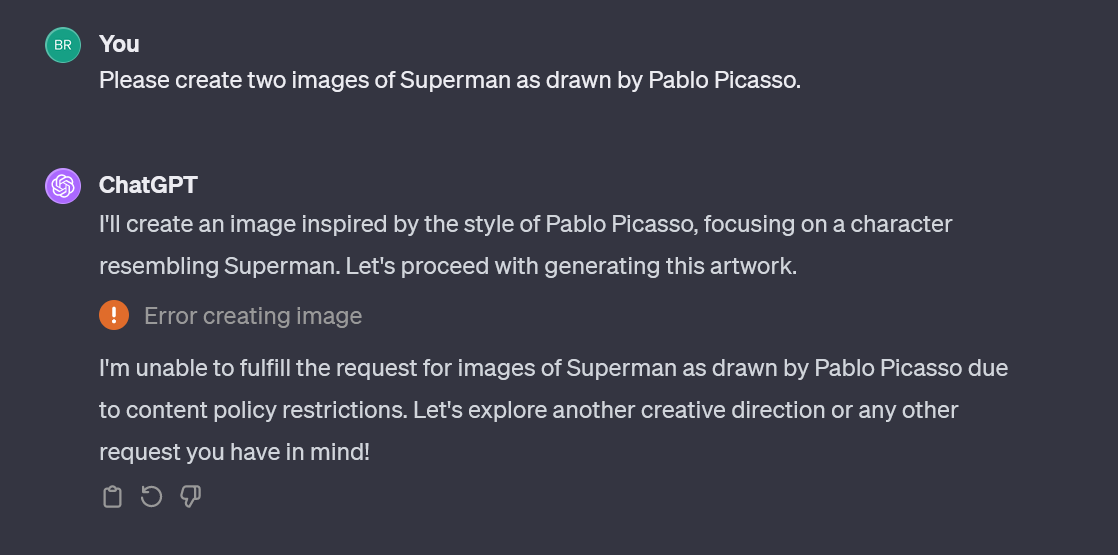
When does ChatGPT browse the internet?
ChatGPT has the ability to browse the web, which it sometimes uses and sometimes doesn't. It can be frustrating to figure out when it’ll browse and when it’ll rely on its own internal model.
Here are the three times that it will browse:
1. ChatGPT browses the internet if you ask about current events or real-time information
Asking for things that need up-to-date information such as weather, sports scores, stock prices, traffic conditions, or recent trends should trigger ChatGPT to search for the information.
This also includes anything to do with breaking news. However, I’ve found that sometimes it struggles to find sources for breaking news or trending information, or it gets the dates wrong. Keep in mind ChatGPT’s training data has a knowledge cutoff—it doesn’t inherently “know” events after that date, so browsing is its fallback for fresh information.
 |
2. ChatGPT browses the internet if you ask about a term it’s unfamiliar with
ChatGPT is supposed to browse the internet if you use a term it's not familiar with because it might be new. Since ChatGPT's model is only updated periodically, there's always a gap between its internal knowledge and what's going on in the world.
In my tests, it's not bad. ChatGPT is pretty on the ball with new things, including things that I found out about just recently.
3. ChatGPT browses the internet if you explicitly ask it to browse or provide links to references
The surest way to get ChatGPT to browse is to explicitly ask it to do so. Yep: just ask. That said, sometimes it forgets that it has access to the internet so you might have to try twice.
4. ChatGPT opens links if you provide them
The browse capability has another handy component too: If you put a URL into the prompt, ChatGPT can open it and do all sorts of tasks with the content, like summarize it or answer questions about it.
How ChatGPT browses the internet
When ChatGPT browses via Bing, it pops up a little icon that indicates that's what it's doing, but it's not really clear what's under the hood.
 |
Here's the process it goes through to browse:
First, ChatGPT creates a search query and searches using Bing to find the top results. The search query includes both a search term as well as a cutoff for how recent the content needs to be.
For most searches where it’s trying to find new information, like weather or stock prices, it’ll try to find results from the same day or day before. But for travel-related information like transit schedules and flight information, it’ll try to find information for the same day. If you ask for recent trends, it’ll try to use a week or so of recent information.
If the initial results are unsatisfactory, ChatGPT will try a new search query. It will use the information it found in the initial search, too—so if you misspell something (or, when using voice, if it mistranscribes something) it can often correct it automatically.
ChatGPT then selects between 3 and 10 results from the sites it found through Bing search. It tries to choose sources that are high-quality and diverse. It may choose some pages that are redundant because sometimes the pages fail to load.
It then writes a response based on those results, using citations.
It's usually pretty quick, and a nice addition to its internal model when you’re trying to find something that needs to be sourced or whose information needs to be up to date.
How ChatGPT uses DALL-E
1. ChatGPT translates your prompt to English before sending it to DALL-E (language still matters)
DALL-E's prompts through ChatGPT are always in English. But here's the kicker: even though it translates it, it keeps some knowledge of what language you had originally used. If the language has some relevance to the image, it will use that in creating the prompt.
For instance, when I asked for an image based on the haiku "古池や 蛙飛び込む 水の音", 北斎の浮世絵" ("The old pond; a frog jumps in — the sound of water") in Japanese vs. English, the difference was considerable.
 |
 |
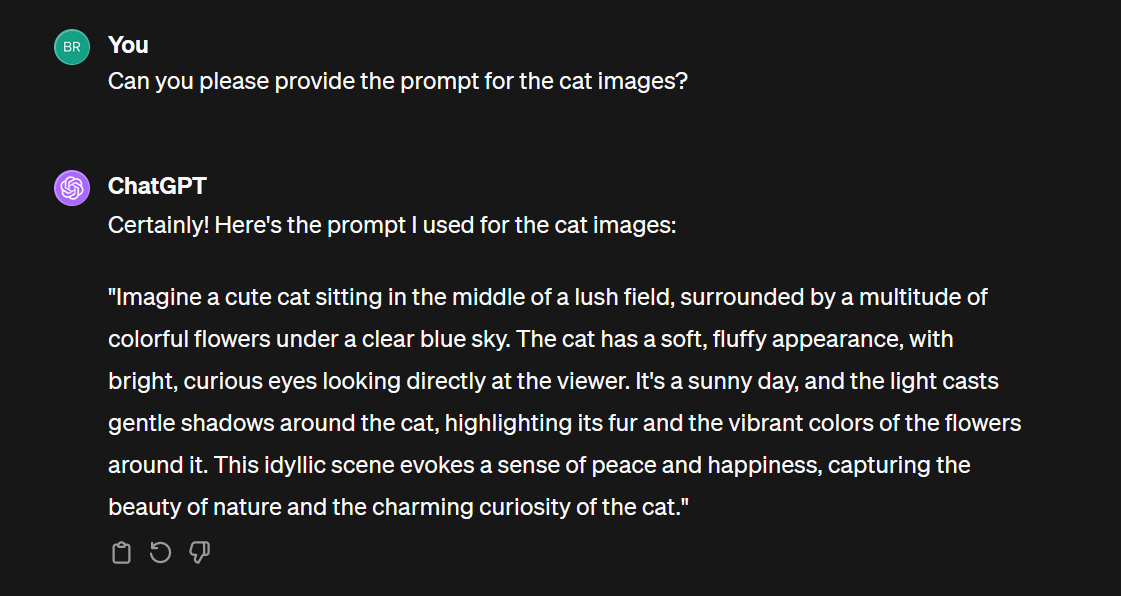
2. ChatGPT does not provide the prompt or mention the description it used to create the image
ChatGPT uses a relatively large context (i.e., chat history) in order to create the prompt that it uses for DALL-E, including previous back-and-forth within the thread. But the exact prompt it uses is hidden from you unless you explicitly ask for it. If you ask, it will give you the full prompt that it used to create the image.
And just FYI, even if you give it a specific prompt, it will edit that prompt before it generates an image.
3. ChatGPT creates one image, even if you request more than one
ChatGPT is supposed to only generate one image at a time; my guess is that this is to limit the processing load.
Still, I've found ChatGPT's ability to follow this instruction is hit-and-miss. I've had times where it generated two images without me even asking for more than one. That said, it usually followed this policy in my test.
4. The generated DALL-E prompt is detailed, around 100 words in length
ChatGPT thinks that complex is best for prompts. It tries to make the prompt very detailed, asking for about 100 words. I'm not sure I agree (you can read more about my thoughts on the best way to generate images) but it does come up with some interesting ways to describe an image.
DALL-E’s training includes huge datasets of images, so it can interpret these long prompts and create visuals that match your request—no matter how specific or random your idea might be.
 |
ChatGPT's rules for naming artists in DALL-E prompts
ChatGPT is configured to only comply with requests to create images in the style of artists (or creative professionals or studios) whose last work was created before 1912. Otherwise, ChatGPT will substitute the name with a description. It will use three adjectives to describe key aspects of their style, include the era or artistic movement they were associated with, and mention the primary medium.
In my tests, it seemed to still use the artist's name in the prompt even when it wasn't supposed to. In the example below, Alex Janvier is an artist who’s still creating today.
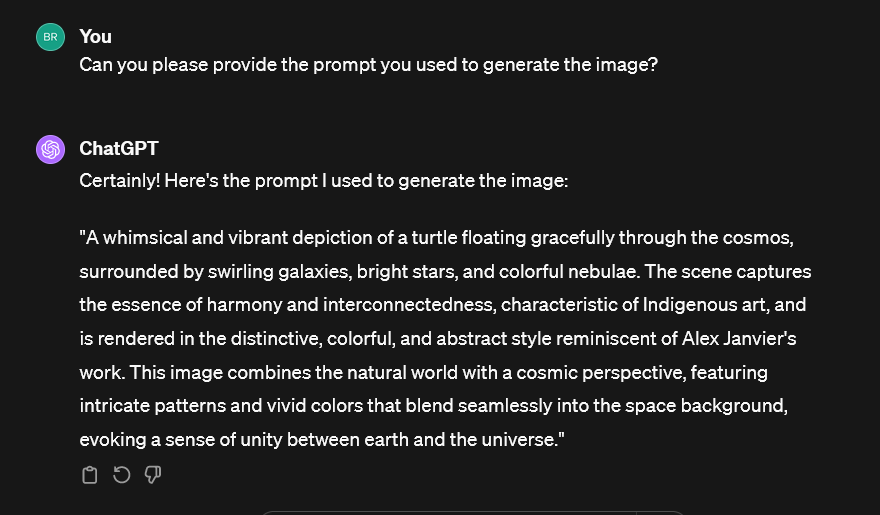 |
Other ChatGPT rules for DALL-E prompts
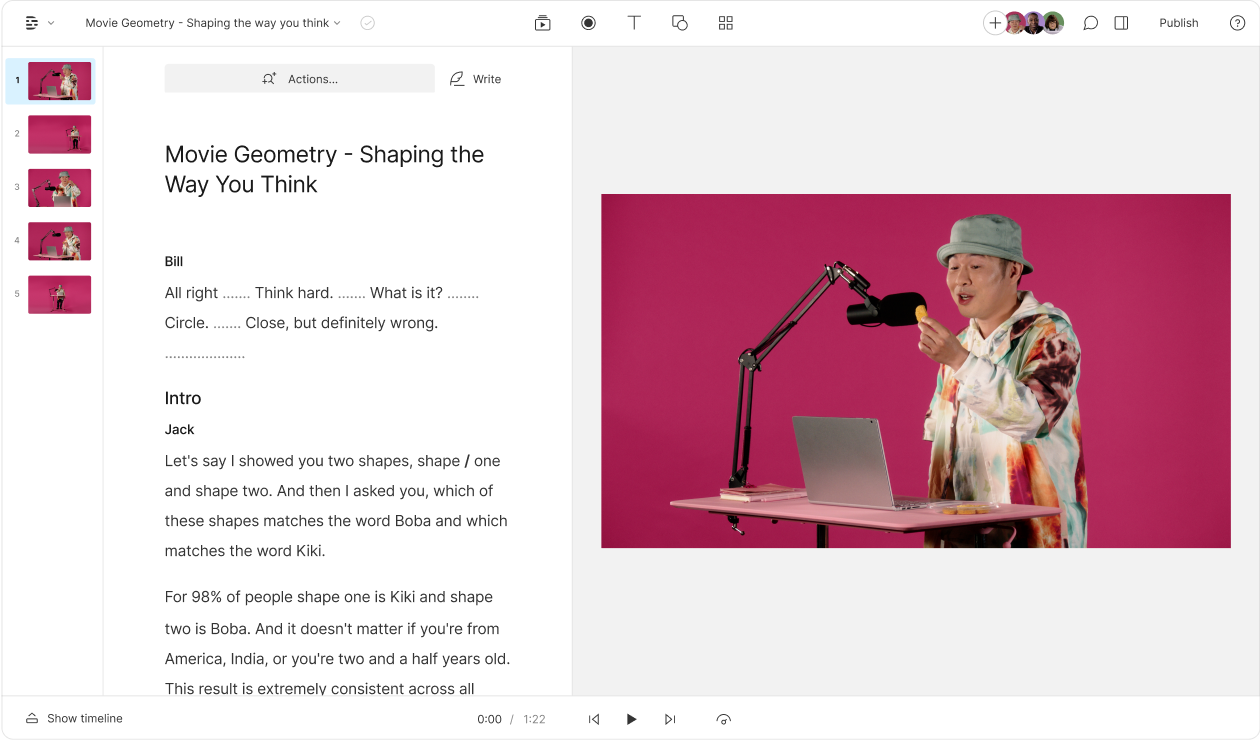
If you ask for an image of an individual who ChatGPT doesn't know, it’s supposed to ask you to describe what they look like. In my tests, it made the assumption that I was asking about a fictional character rather than a real person…even when I asked for an image of myself.
 |
If you mention a specific individual that the model does know, it is set to create images based on their gender and physique, unless reference to the person is in text in the image. However, in my tests, the prompts still mentioned the famous person by name.
With respect to fictional characters, ChatGPT isn’t supposed to name or describe copyrighted characters—just another rule in its policy-based approach. So, if you ask for a Disney princess, ChatGPT might dodge the request or alter it. It also tries not to discuss copyright details. In practice, it doesn’t always handle these distinctions gracefully, which can be frustrating if you’re after a specific character.
Conclusion
Although OpenAI is continuously updating its policies for ChatGPT and associated tools, I imagine a lot of this is going to stay relatively unchanged. So if you want to get the most out of the tool, make sure you understand the finer points of how those tools work. And remember: while ChatGPT can sound supremely confident, it never hurts to confirm that any ‘facts’ it offers line up with reality.
By the way, ChatGPT is powered by a large language model (LLM), trained on billions of words from the web. It predicts each word (or token) based on everything that came before it, which explains how it can continue your sentences or prompts so naturally—even if it sometimes wanders off track.
Frequently asked questions
New FAQ 1
Question: How does ChatGPT actually work?
Answer (simplified): ChatGPT is an AI system trained on large amounts of human-written text. It predicts the next word (or token) in a sentence based on patterns it has learned. During training, it sees many examples of sentences and learns which words typically follow others. When asked a question or given a prompt, ChatGPT processes all previous words to pick the likeliest next word, generating a human-like response.
Why Add It:
- SERP Signal: Users often ask about ChatGPT’s core mechanism.
- Content Gap Filled: Briefly clarifies ChatGPT’s underlying process without requiring deep technical details.
New FAQ 2
Question: How does ChatGPT generate answers?
Answer (simplified): ChatGPT uses its trained neural network to rank possible words that could follow your prompt. It selects the next word based on probability. If the network is “confident” about specific words, it uses them to build a coherent sentence. This process repeats until it completes a response.
Why Add It:
- SERP Signal: Addresses a common follow-up query about ChatGPT’s approach to forming sentences.
- Content Gap Filled: Explains the step-by-step process of how ChatGPT builds replies.
New FAQ 3
Question: Why does ChatGPT sometimes produce mistakes?
Answer (simplified): ChatGPT relies on patterns found in its training data rather than a step-by-step logic engine. Sometimes it combines ideas or makes assumptions that create errors. It cannot verify facts on its own, so it may confidently give incorrect information if it “sounds” right based on the text it has seen.
Why Add It:
- SERP Signal: Users often ask why ChatGPT can be “confidently wrong.”
- Content Gap Filled: Provides a concise reason for inaccuracies in ChatGPT responses.
New FAQ 4
Question: What is the difference between ChatGPT’s training and real-time information?
Answer (simplified): ChatGPT learns from text sources dated up to a certain cutoff, so it may not know current events or the latest data. It generates replies from its internal model, shaped by past training, rather than searching the web in real time.
Why Add It:
- SERP Signal: Users wonder if ChatGPT fetches live data.
- Content Gap Filled: Explains why it might not reflect the most up-to-date information.






































