Anyone in audio or video production has experienced the frustration of reviewing tape and finding just the right sound bite for a story… if only the speaker hadn’t flubbed some words or forgotten to mention something crucial at the right time. Sometimes the only choice is to go through the effort of re-recording or leaving out the almost-perfect sound bite altogether.
Here at Lyrebird, the AI research division of Descript, we’ve been working on a solution to this problem. Since its initial launch, Descript lets a user automatically modify media by simply editing the text. Someone editing audio or video can remove words from the transcript and Descript automatically removes the corresponding portion from the media.
We thought, what if Descript users could not only remove words, but add completely new words from scratch without having to record anything new? This would make editing much faster and more convenient — no additional recording sessions to organize!
This is the challenge we have been tackling for the last few months, and we are excited to announce that the Descript now includes this new Overdub feature in private beta.
Text-informed speech inpainting
From a research perspective, this problem is called text-informed speech inpainting. Let’s say that you want to insert new words in the middle of a sentence, potentially removing words at the same time — the goal of inpainting is to generate the missing audio of the edited sentence, so that the result sounds as natural as possible. Perfect inpainting would mean that anyone listening to the audio would not be capable of detecting which words were generated and which were not.
Surprisingly, there has been little research on the topic of text-informed speech inpainting to date, while similar problems in vision or natural language processing have already been explored, including:
- Removing a portion of an image and generating it (image-inpainting)
- Removing words in a text sentence and generating new words (text-imputation)
- Removing audio portions in an audio file and re-generating them (audio-imputation, audio-inpainting, denoising)
A key difference is that text-informed speech inpainting, where the user edits a sentence to generate audio, combines two data types at the same time: text and audio. In other words, it is audio inpainting conditioned on text.
The challenges
Text-informed speech inpainting is challenging for a number of reasons:
- The generated audio needs to be as close as possible to the original voice, implying that the voice of the user has to be cloned and that the quality of the text-to-speech model has to be very high.
- The resulting sentence should sound as natural as possible. Adding words or removing others might change the overall intonation of the sentence. This means that potentially some original parts of the audio might need to be modified as well to match the new intonation of the sentence.
- Locally, at the boundaries of the inpainting, there should not be any pop or discontinuity.
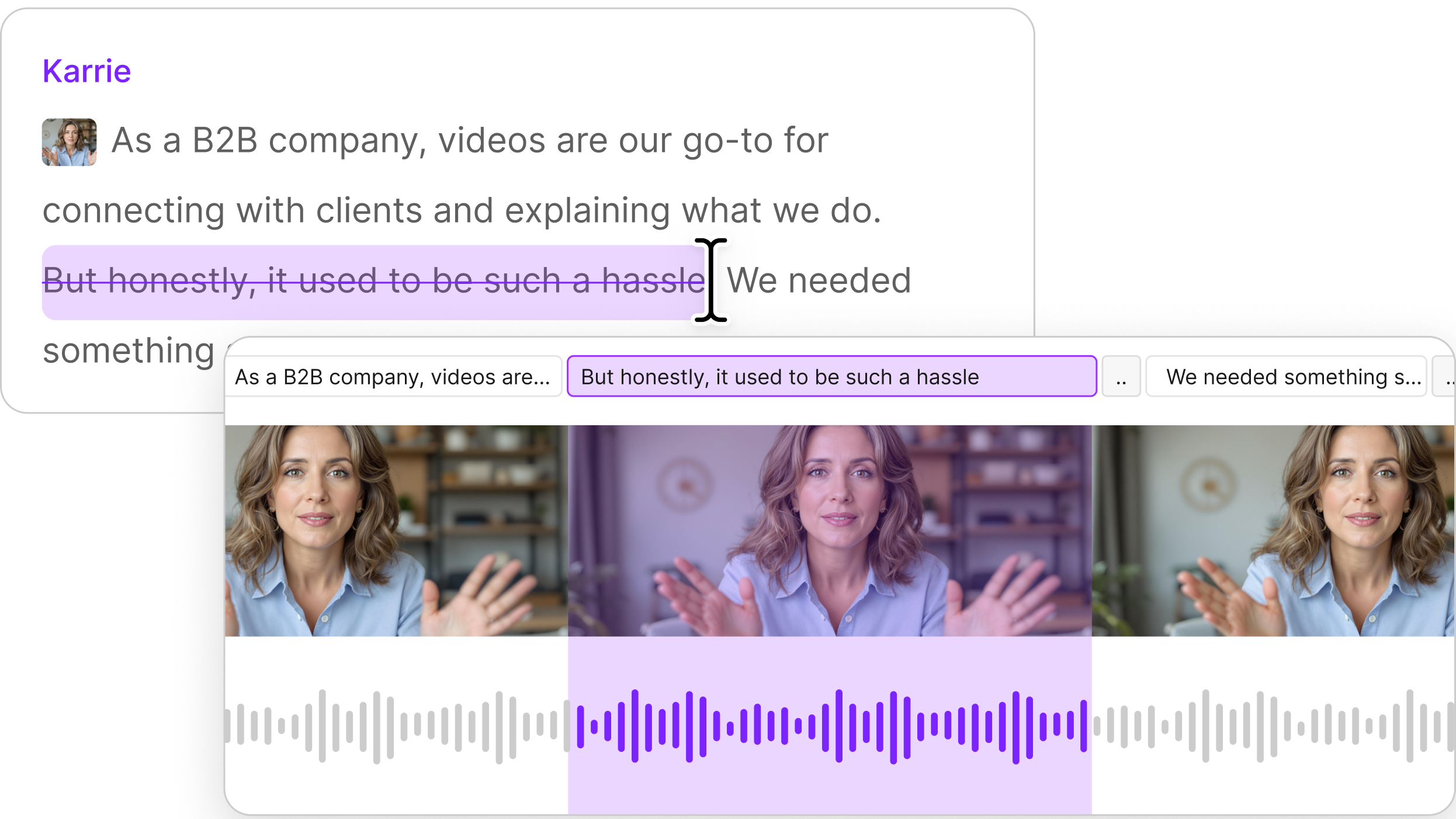
Technically, text-informed speech inpainting can be formulated in the following fashion: a user has an original text sentence and corresponding speech audio, then removes a few words and replaces them with new ones. The parts of the audio that are kept untouched are called the prefix and the suffix. The prefix is the chunk before the inpainting (the “left” part) while the suffix is the one after (the “right” part). This means there is prefix text and prefix audio, and respectively suffix text and suffix audio.

Therefore, all of our models have the following inputs: prefix text and audio, suffix text and audio, and new text. They all return the generated audio portion. The resulting audio sentence is the concatenation of the prefix audio, the generated audio, and the suffix audio. We call the left and right boundaries concatenation points.
To solve this task, we explored two main strategies:
- Inpainting using attention with bidirectional style models
- Inpainting without using attention
1. Inpainting using attention with bidirectional style models
Unidirectional text-to-speech
A simple approach to tackle the inpainting task is to:
- Train a standard left-to-right, text-to-speech (TTS) autoregressive neural network to mimic the voice of the user (e.g. char2wav, tacotron, or transformer models).
- Use teacher forcing on the prefix audio (with attention spanning the whole text).
- Generate the inpainted part by initializing the hidden states with those returned by the teacher forcing step. The hidden state summarizes both the local and global intonations of the left prefix.
Although the approach makes the left boundary sound natural and smooth, the right boundary is a discontinuity point both locally and globally:
- Locally: It is not trivial to decide when to stop the generation of the inpainting portion and, as a result, the silence between the last inpainted word and the first suffix word is often inadequate, either too long or too short. Plus, there might also be a pop or discontinuity at the boundary due to the fact that we are naively concatenating two audio files.
- Globally: The intonation of the generated words might not match that of the suffix. During generation, the network doesn’t have access to the suffix audio (although, thanks to attention, it has access to the suffix text). For example, we might have a happy-sounding prefix, and thus a happy inpainted part, whereas the suffix sounds sad, producing an overall unnatural audio.
Bidirectional models

To tackle the discontinuity issue at the right boundary, we developed a model composed of two decoders processing the audio in each direction respectively: one generates the audio from left to right, while the other generates the audio from right to left. This makes the left and right boundaries smooth but creates a new problem: How do we decide when to stop the two decoders, and how do we make sure that this new “middle boundary” sounds natural both locally and globally?
For the stopping criterion, the idea is to decide based on the attention: the decoders share weights, so that both of their attentions are compatible. Both decoders generate timesteps in turn, and we stop generation when they both meet at the middle, i.e. just before one decoder starts generating something already generated by the other.
Regarding the overall naturalness of the intonation and local discontinuity, we make the two decoders communicate via the following mechanism: At each timestep, we feed the current decoder with the state and attention of the other so that the current decoder gets a sense of where the other decoder is and what intonation it has. This way, decoders can synchronize themselves and make sure that they meet smoothly with the right intonation.
Style-based models
To further improve intonation, we enhanced our bidirectional models by feeding the decoders extra inputs that capture the prosodic style of the prefix and suffix. The idea is to use an extra encoder to summarize the style of the prefix and suffix into fixed-length “style vectors” and then use those at each timestep of the decoder.
2. Inpainting without using attention to align text and audio
One possible restriction with the first strategy is that the model has to devote a fair amount of capacity to learn an alignment between the audio and the corresponding text. Therefore, we investigated a different architecture where the work is split between two networks.
First, a duration predictor network is used to predict the duration of each phoneme in the utterance to be generated. This is accomplished by a feedforward network, which attends to various conditioning information (prefix text, suffix audio, suffix text, and prefix audio) as available. A softmax layer is applied at the very end to predict each phoneme’s duration.
Then, another network, composed of a feedforward feature extractor and a final autoregressive layer is used to predict the audio sequence.
Between the networks, we introduced an upsampling layer, which upsamples the text sequence to be imputed to match the audio sequence. During training, the ground truth alignment between text and audio is used to carry out the upsampling. During generation, the predicted alignment (obtained from the prediction of each phoneme’s duration) is used to carry out the upsampling.
Experimentally, we found that the resulting audio fidelity and intonation are very good, without significant glitches at the boundary. We attribute this to the fact that the model has full access to the left and right information, and can devote all of its capacity to modeling the audio sequence without having to worry about intonation.
Conclusion
Overdub is one of the AI features we have been working on to enable new ways of creative expression. It’s exciting because it’s the very first time that such a feature has become available to users and we believe it will change the way we create and edit media content. If you would like to hear about what we do and our career offers, read more here.